Reproducible Builds: Reproducible Builds in August 2021
 Welcome to the latest report from the Reproducible Builds project. In this post, we round up the important things that happened in the world of reproducible builds in August 2021. As always, if you are interested in contributing to the project, please visit the Contribute page on our website.
Welcome to the latest report from the Reproducible Builds project. In this post, we round up the important things that happened in the world of reproducible builds in August 2021. As always, if you are interested in contributing to the project, please visit the Contribute page on our website.
 There were a large number of talks related to reproducible builds at DebConf21 this year, the 21st annual conference of the Debian Linux distribution (full schedule):
There were a large number of talks related to reproducible builds at DebConf21 this year, the 21st annual conference of the Debian Linux distribution (full schedule):
- Firstly, Holger Levsen gave a talk titled Reproducible Buster, Bullseye & Bookworm - where we come from and where we are going (slides) which provided a high-level update on the status of reproducible builds within Debian, summing up the status in Debian Buster, Bullseye and then spoke about the outlook for Bookworm. This talk was also given at BornHack 2021 on the Danish island of Funen (schedule entry, video)
- Secondly, Vagrant Cascadian gave a talk titled Looking Forward to Reproducible Builds which mentions some historic blockers within Debian that have been solved, worked around or which are still in progress. It also touched on some recent developments, with an eye to what might happen as Debian embarks upon the new Bookworm development cycle after the release of Bullseye.
-
Lastly, Johannes Schauer Marin Rodrigues & Fr d ric Pierret gave a joint talk on Making use of
snapshot.debian.orgfor fun and profit about various tools they have developed to interact with the snapshot.debian.org wayback machine for Debian packages. In particular, they mention how they are using the service to reproduce and validate builds as well as touch on an alternative snapshot service that has been mentioned in previous reports.
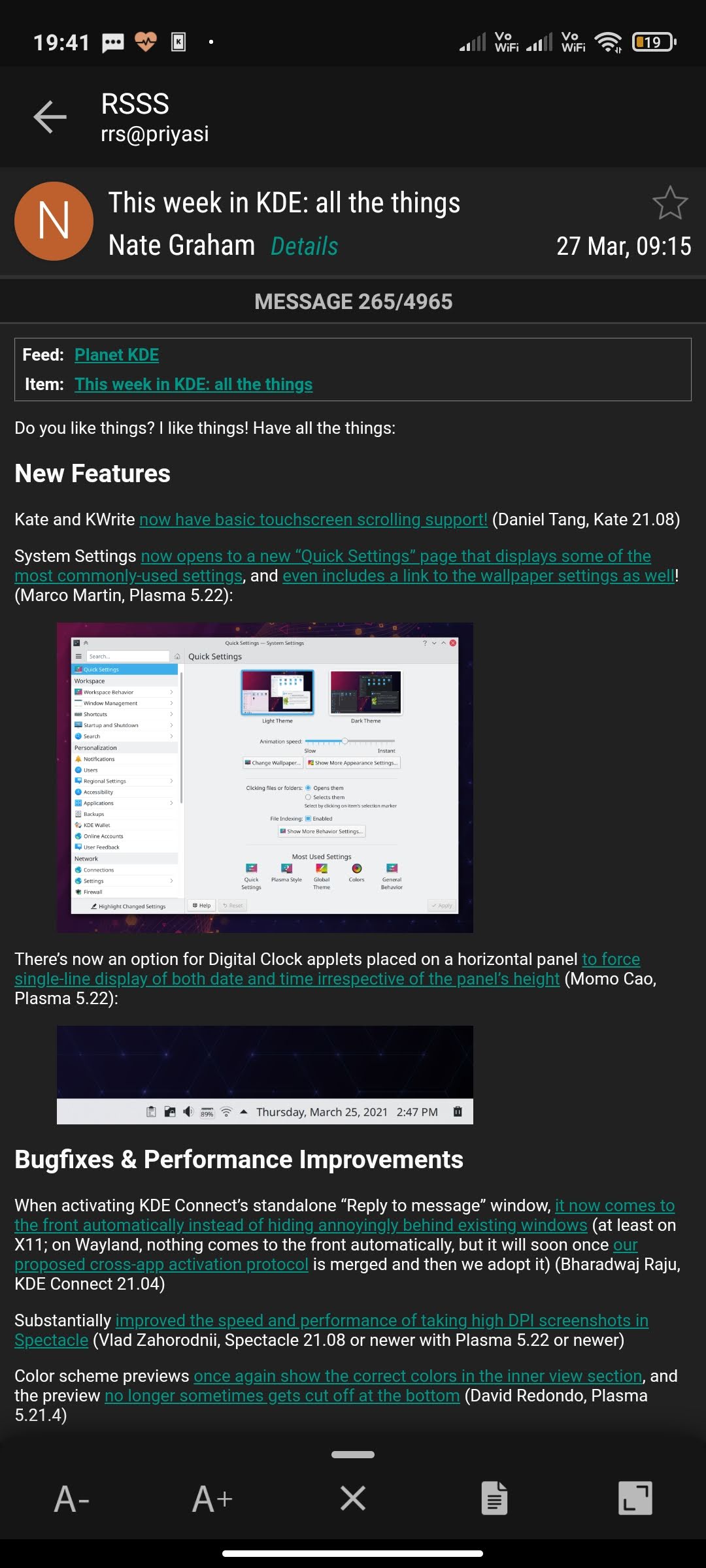
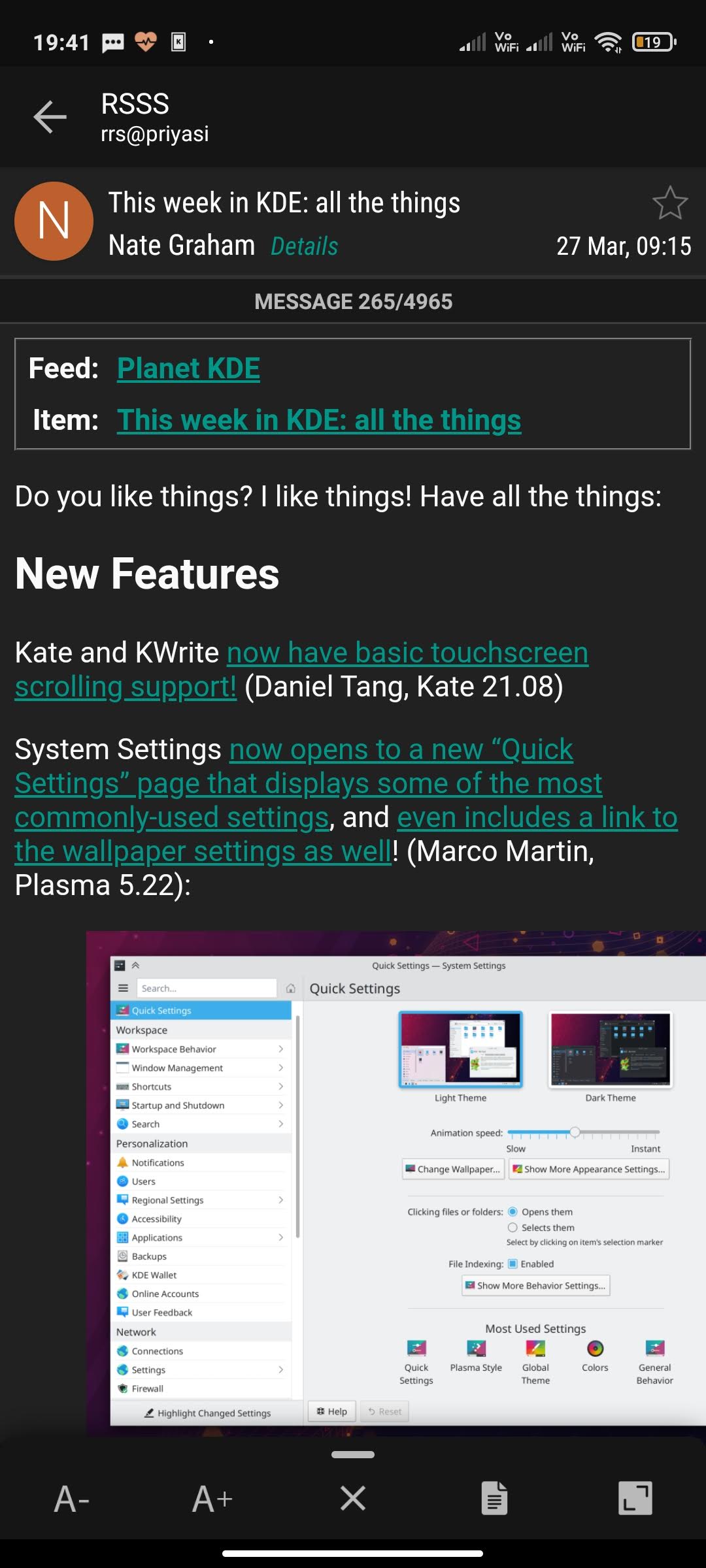
 PackagingCon (@PackagingCon) is new conference for developers of package management software as well as their related communities and stakeholders. The virtual event, which is scheduled to take place on the 9th and 10th November 2021, has a mission is to bring different ecosystems together: from Python s pip to Rust s cargo to Julia s Pkg, from Debian apt over Nix to conda and mamba, and from vcpkg to Spack we hope to have many different approaches to package management at the conference . A number of people from reproducible builds community are planning on attending this new conference, and some may even present. Tickets start at $20 USD.
PackagingCon (@PackagingCon) is new conference for developers of package management software as well as their related communities and stakeholders. The virtual event, which is scheduled to take place on the 9th and 10th November 2021, has a mission is to bring different ecosystems together: from Python s pip to Rust s cargo to Julia s Pkg, from Debian apt over Nix to conda and mamba, and from vcpkg to Spack we hope to have many different approaches to package management at the conference . A number of people from reproducible builds community are planning on attending this new conference, and some may even present. Tickets start at $20 USD.
 As reported in our May report, the president of the United States signed an executive order outlining policies aimed to improve the cybersecurity in the US. The executive order comes after a number of highly-publicised security problems such as a ransomware attack that affected an oil pipeline between Texas and New York and the SolarWinds hack that affected a large number of US federal agencies. As a followup this month, however, a detailed fact sheet was released announcing a number large-scale initiatives and that will undoubtedly be related to software supply chain security and, as a result, reproducible builds.
As reported in our May report, the president of the United States signed an executive order outlining policies aimed to improve the cybersecurity in the US. The executive order comes after a number of highly-publicised security problems such as a ransomware attack that affected an oil pipeline between Texas and New York and the SolarWinds hack that affected a large number of US federal agencies. As a followup this month, however, a detailed fact sheet was released announcing a number large-scale initiatives and that will undoubtedly be related to software supply chain security and, as a result, reproducible builds.
 Lastly, We ran another productive meeting on IRC in August (original announcement) which ran for just short of two hours. A full set of notes from the meeting is available.
Lastly, We ran another productive meeting on IRC in August (original announcement) which ran for just short of two hours. A full set of notes from the meeting is available.
Software development
kpcyrd announced an interesting new project this month called I probably didn t backdoor this which is an attempt to be:
a practical attempt at shipping a program and having reasonably solid evidence there s probably no backdoor. All source code is annotated and there are instructions explaining how to use reproducible builds to rebuild the artifacts distributed in this repository from source.
The idea is shifting the burden of proof from you need to prove there s a backdoor to we need to prove there s probably no backdoor . This repository is less about code (we re going to try to keep code at a minimum actually) and instead contains technical writing that explains why these controls are effective and how to verify them. You are very welcome to adopt the techniques used here in your projects. ( )
As the project s README goes on the mention: the techniques used to rebuild the binary artifacts are only possible because the builds for this project are reproducible . This was also announced on our mailing list this month in a thread titled i-probably-didnt-backdoor-this: Reproducible Builds for upstreams.
 kpcyrd also wrote a detailed blog post about the problems surrounding Linux distributions (such as Alpine and Arch Linux) that distribute compiled Python bytecode in the form of
kpcyrd also wrote a detailed blog post about the problems surrounding Linux distributions (such as Alpine and Arch Linux) that distribute compiled Python bytecode in the form of .pyc files generated during the build process.
diffoscope
 diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb made a number of changes, including releasing version 180), version 181) and version 182) as well as the following changes:
diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb made a number of changes, including releasing version 180), version 181) and version 182) as well as the following changes:
-
New features:
- Add support for extracting the signing block from Android APKs. [ ]
- If we specify a suffix for a temporary file or directory within the code, ensure it starts with an underscore (ie. _ ) to make the generated filenames more human-readable. [ ]
- Don t include short
GCC lines that differ on a single prefix byte either. These are distracting, not very useful and are simply the strings(1) command s idea of the build ID, which is displayed elsewhere in the diff. [ ][ ]
- Don t include specific
.debug-like lines in the ELF-related output, as it is invariably a duplicate of the debug ID that exists better in the readelf(1) differences for this file. [ ]
-
Bug fixes:
- Add a special case to SquashFS image extraction to not fail if we aren t the superuser. [ ]
- Only use
java -jar /path/to/apksigner.jar if we have an apksigner.jar as newer versions of apksigner in Debian use a shell wrapper script which will be rejected if passed directly to the JVM. [ ]
- Reduce the maximum line length for calculating Wagner-Fischer, improving the speed of output generation a lot. [ ]
- Don t require
apksigner in order to compare .apk files using apktool. [ ]
- Update calls (and tests) for the new version of
odt2txt. [ ]
-
Output improvements:
-
Logging improvements:
-
Codebase improvements:
- Clarify a comment about the
HUGE_TOOLS Python dictionary. [ ]
- We can pass
-f to apktool to avoid creating a strangely-named subdirectory. [ ]
- Drop an unused
File import. [ ]
- Update the supported & minimum version of Black. [ ]
- We don t use the
logging variable in a specific place, so alias it to an underscore (ie. _ ) instead. [ ]
- Update some various copyright years. [ ]
- Clarify a comment. [ ]
-
Test improvements:
- Update a test to check specific contents of SquashFS listings, otherwise it fails depending on the test systems user ID to username
passwd(5) mapping. [ ]
- Assign seen and expected values to local variables to improve contextual information in failed tests. [ ]
- Don t print an orphan newline when the source code formatting test passes. [ ]
In addition Santiago Torres Arias added support for Squashfs version 4.5 [ ] and Felix C. Stegerman suggested a number of small improvements to the output of the new APK signing block [ ]. Lastly, Chris Lamb uploaded python-libarchive-c version 3.1-1 to Debian experimental for the new 3.x branch python-libarchive-c is used by diffoscope.
Distribution work
 In Debian, 68 reviews of packages were added, 33 were updated and 10 were removed this month, adding to our knowledge about identified issues. Two new issue types have been identified too: nondeterministic_ordering_in_todo_items_collected_by_doxygen and kodi_package_captures_build_path_in_source_filename_hash.
kpcyrd published another monthly report on their work on reproducible builds within the Alpine and Arch Linux distributions, specifically mentioning rebuilderd, one of the components powering reproducible.archlinux.org. The report also touches on binary transparency, an important component for supply chain security.
The @GuixHPC account on Twitter posted an infographic on what fraction of GNU Guix packages are bit-for-bit reproducible:
In Debian, 68 reviews of packages were added, 33 were updated and 10 were removed this month, adding to our knowledge about identified issues. Two new issue types have been identified too: nondeterministic_ordering_in_todo_items_collected_by_doxygen and kodi_package_captures_build_path_in_source_filename_hash.
kpcyrd published another monthly report on their work on reproducible builds within the Alpine and Arch Linux distributions, specifically mentioning rebuilderd, one of the components powering reproducible.archlinux.org. The report also touches on binary transparency, an important component for supply chain security.
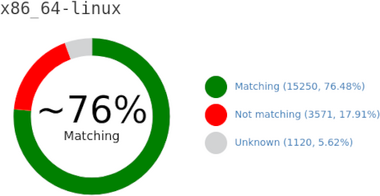
The @GuixHPC account on Twitter posted an infographic on what fraction of GNU Guix packages are bit-for-bit reproducible:
 Finally, Bernhard M. Wiedemann posted his monthly reproducible builds status report for openSUSE.
Finally, Bernhard M. Wiedemann posted his monthly reproducible builds status report for openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
awkward (timestamp issue)ck (build fails in single-CPU mode)cri-o (build ID issue related to Go parallelism)kernel-obs-build (cpio metadata issue)python-PyQt6 (.pyc-related issue)python-dulwich (fails to build in 2023)python-xkbgroup (.pyc-related issue)rnp (fails to build in 2024)
-
Bj rn Forsman:
dosfstools (from December 2018) was eventually merged.
-
Chris Lamb:
- #992039 filed against
mapcache.
- #992059 filed against
spatialindex.
- #992060 filed against
pytsk.
- #992061 filed against
surgescript.
- #992126 filed against
rust-coreutils.
- #992772 filed against
translate.
- #992773 filed against
spirv-cross.
- #992804 filed against
numcodecs.
- #993279 filed against
tty-solitaire.
- #993304 filed against
samtools.
-
Simon McVittie:
- #992620 filed against
pkg-config.
- #992622 filed against
pkgconf.
- #992645 filed against
ncftp.
- #992647 filed against
backuppc.
- #992651 filed against
sharutils.
- #992662 filed against
cfengine3.
- #992702 filed against
nbdkit.
- #992722 filed against
nbdkit.
- #992775 filed against
python3.9.
- #992781 filed against
supermin.
- #992782 filed against
virt-p2v.
- #993249 filed against
gnunet.
- #993250 filed against
mpb.
- #993275 filed against
ng.
-
Vagrant Cascadian:
 Elsewhere, it was discovered that when supporting various new language features and APIs for Android apps, the resulting APK files that are generated now vary wildly from build to build (example diffoscope output). Happily, it appears that a patch has been committed to the relevant source tree. This was also discussed on our mailing list this month in a thread titled Android desugaring and reproducible builds started by Marcus Hoffmann.
Elsewhere, it was discovered that when supporting various new language features and APIs for Android apps, the resulting APK files that are generated now vary wildly from build to build (example diffoscope output). Happily, it appears that a patch has been committed to the relevant source tree. This was also discussed on our mailing list this month in a thread titled Android desugaring and reproducible builds started by Marcus Hoffmann.
Website and documentation
 There were quite a few changes to the Reproducible Builds website and documentation this month, including:
There were quite a few changes to the Reproducible Builds website and documentation this month, including:
-
Felix C. Stegerman:
-
Holger Levsen:
- Add a new page documenting various package rebuilder solutions. [ ]
- Add some historical talks and slides from DebConf20. [ ][ ]
- Various improvements to the history page. [ ][ ][ ]
- Rename the Comparison protocol documentation category to Verification . [ ]
- Update links to F-Droid documentation. [ ]
-
Ian Muchina:
-
Mattia Rizzolo:
- Drop a
position:fixed CSS statement that is negatively affecting with some width settings. [ ]
- Fix the sizing of the elements inside the side navigation bar. [ ]
- Show gold level sponsors and above in the sidebar. [ ]
- Updated the documentation within
reprotest to mention how ldconfig conflicts with the kernel variation. [ ]
-
Roland Clobus:
- Added a ticket number for the issue with the live Cinnamon image and diffoscope. [ ]
Testing framework
 The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
-
Holger Levsen:
-
Debian-related changes:
- Make a large number of changes to support the new Debian bookworm release, including adding it to the dashboard [ ], start scheduling tests [ ], adding suitable Apache redirects [ ] etc. [ ][ ][ ][ ][ ]
- Make the first build use
LANG=C.UTF-8 to match the official Debian build servers. [ ]
- Only test Debian Live images once a week. [ ]
- Upgrade all nodes to use Debian Bullseye [ ] [ ]
- Update README documentation for the Debian Bullseye release. [ ]
-
Other changes:
- Only include
rsync output if the $DEBUG variable is enabled. [ ]
- Don t try to install
mock, a tool used to build Fedora packages some time ago. [ ]
- Drop an unused function. [ ]
- Various documentation improvements. [ ][ ]
- Improve the node health check to detect zombie jobs. [ ]
-
Jessica Clarke (FreeBSD-related changes):
-
Mattia Rizzolo:
- Block F-Droid jobs from running whilst the setup is running. [ ]
- Enable debugging for the
rsync job related to Debian Live images. [ ]
- Pass
BUILD_TAG and BUILD_URL environment for the Debian Live jobs. [ ]
- Refactor the
master_wrapper script to use a Bash array for the parameters. [ ]
- Prefer YAML s
safe_load() function over the unsafe variant. [ ]
- Use the correct variable in the Apache config to match possible existing files on disk. [ ]
- Stop issuing HTTP 301 redirects for things that not actually permanent. [ ]
-
Roland Clobus (Debian live image generation):
- Increase the diffoscope timeout from 120 to 240 minutes; the Cinnamon image should now be able to finish. [ ]
- Use the new snapshot service. [ ]
- Make a number of improvements to artifact handling, such as moving the artifacts to the Jenkins host [ ] and correctly cleaning them up at the right time. [ ][ ][ ]
- Where possible, link to the Jenkins build URL that created the artifacts. [ ][ ]
- Only allow only one job to run at the same time. [ ]
-
Vagrant Cascadian:
- Temporarily disable
armhf nodes for DebConf21. [ ][ ]
Lastly, if you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. You can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter (@ReproBuilds) and Mastodon (@reproducible_builds@fosstodon.org).
-
Reddit: /r/ReproducibleBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb made a number of changes, including releasing version 180), version 181) and version 182) as well as the following changes:
-
New features:
- Add support for extracting the signing block from Android APKs. [ ]
- If we specify a suffix for a temporary file or directory within the code, ensure it starts with an underscore (ie. _ ) to make the generated filenames more human-readable. [ ]
- Don t include short
GCClines that differ on a single prefix byte either. These are distracting, not very useful and are simply the strings(1) command s idea of the build ID, which is displayed elsewhere in the diff. [ ][ ] - Don t include specific
.debug-like lines in the ELF-related output, as it is invariably a duplicate of the debug ID that exists better in thereadelf(1)differences for this file. [ ]
-
Bug fixes:
- Add a special case to SquashFS image extraction to not fail if we aren t the superuser. [ ]
- Only use
java -jar /path/to/apksigner.jarif we have anapksigner.jaras newer versions ofapksignerin Debian use a shell wrapper script which will be rejected if passed directly to the JVM. [ ] - Reduce the maximum line length for calculating Wagner-Fischer, improving the speed of output generation a lot. [ ]
- Don t require
apksignerin order to compare.apkfiles usingapktool. [ ] - Update calls (and tests) for the new version of
odt2txt. [ ]
- Output improvements:
- Logging improvements:
-
Codebase improvements:
- Clarify a comment about the
HUGE_TOOLSPython dictionary. [ ] - We can pass
-fto apktool to avoid creating a strangely-named subdirectory. [ ] - Drop an unused
Fileimport. [ ] - Update the supported & minimum version of Black. [ ]
- We don t use the
loggingvariable in a specific place, so alias it to an underscore (ie. _ ) instead. [ ] - Update some various copyright years. [ ]
- Clarify a comment. [ ]
- Clarify a comment about the
-
Test improvements:
- Update a test to check specific contents of SquashFS listings, otherwise it fails depending on the test systems user ID to username
passwd(5)mapping. [ ] - Assign seen and expected values to local variables to improve contextual information in failed tests. [ ]
- Don t print an orphan newline when the source code formatting test passes. [ ]
- Update a test to check specific contents of SquashFS listings, otherwise it fails depending on the test systems user ID to username
In addition Santiago Torres Arias added support for Squashfs version 4.5 [ ] and Felix C. Stegerman suggested a number of small improvements to the output of the new APK signing block [ ]. Lastly, Chris Lamb uploaded
python-libarchive-c version 3.1-1 to Debian experimental for the new 3.x branch python-libarchive-c is used by diffoscope.
Distribution work
In Debian, 68 reviews of packages were added, 33 were updated and 10 were removed this month, adding to our knowledge about identified issues. Two new issue types have been identified too: nondeterministic_ordering_in_todo_items_collected_by_doxygen and kodi_package_captures_build_path_in_source_filename_hash.
kpcyrd published another monthly report on their work on reproducible builds within the Alpine and Arch Linux distributions, specifically mentioning rebuilderd, one of the components powering reproducible.archlinux.org. The report also touches on binary transparency, an important component for supply chain security.
The @GuixHPC account on Twitter posted an infographic on what fraction of GNU Guix packages are bit-for-bit reproducible:
Finally, Bernhard M. Wiedemann posted his monthly reproducible builds status report for openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
awkward (timestamp issue)ck (build fails in single-CPU mode)cri-o (build ID issue related to Go parallelism)kernel-obs-build (cpio metadata issue)python-PyQt6 (.pyc-related issue)python-dulwich (fails to build in 2023)python-xkbgroup (.pyc-related issue)rnp (fails to build in 2024)
-
Bj rn Forsman:
dosfstools (from December 2018) was eventually merged.
-
Chris Lamb:
- #992039 filed against
mapcache.
- #992059 filed against
spatialindex.
- #992060 filed against
pytsk.
- #992061 filed against
surgescript.
- #992126 filed against
rust-coreutils.
- #992772 filed against
translate.
- #992773 filed against
spirv-cross.
- #992804 filed against
numcodecs.
- #993279 filed against
tty-solitaire.
- #993304 filed against
samtools.
-
Simon McVittie:
- #992620 filed against
pkg-config.
- #992622 filed against
pkgconf.
- #992645 filed against
ncftp.
- #992647 filed against
backuppc.
- #992651 filed against
sharutils.
- #992662 filed against
cfengine3.
- #992702 filed against
nbdkit.
- #992722 filed against
nbdkit.
- #992775 filed against
python3.9.
- #992781 filed against
supermin.
- #992782 filed against
virt-p2v.
- #993249 filed against
gnunet.
- #993250 filed against
mpb.
- #993275 filed against
ng.
-
Vagrant Cascadian:
Elsewhere, it was discovered that when supporting various new language features and APIs for Android apps, the resulting APK files that are generated now vary wildly from build to build (example diffoscope output). Happily, it appears that a patch has been committed to the relevant source tree. This was also discussed on our mailing list this month in a thread titled Android desugaring and reproducible builds started by Marcus Hoffmann.
Website and documentation
There were quite a few changes to the Reproducible Builds website and documentation this month, including:
-
Felix C. Stegerman:
-
Holger Levsen:
- Add a new page documenting various package rebuilder solutions. [ ]
- Add some historical talks and slides from DebConf20. [ ][ ]
- Various improvements to the history page. [ ][ ][ ]
- Rename the Comparison protocol documentation category to Verification . [ ]
- Update links to F-Droid documentation. [ ]
-
Ian Muchina:
-
Mattia Rizzolo:
- Drop a
position:fixed CSS statement that is negatively affecting with some width settings. [ ]
- Fix the sizing of the elements inside the side navigation bar. [ ]
- Show gold level sponsors and above in the sidebar. [ ]
- Updated the documentation within
reprotest to mention how ldconfig conflicts with the kernel variation. [ ]
-
Roland Clobus:
- Added a ticket number for the issue with the live Cinnamon image and diffoscope. [ ]
Testing framework
The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
-
Holger Levsen:
-
Debian-related changes:
- Make a large number of changes to support the new Debian bookworm release, including adding it to the dashboard [ ], start scheduling tests [ ], adding suitable Apache redirects [ ] etc. [ ][ ][ ][ ][ ]
- Make the first build use
LANG=C.UTF-8 to match the official Debian build servers. [ ]
- Only test Debian Live images once a week. [ ]
- Upgrade all nodes to use Debian Bullseye [ ] [ ]
- Update README documentation for the Debian Bullseye release. [ ]
-
Other changes:
- Only include
rsync output if the $DEBUG variable is enabled. [ ]
- Don t try to install
mock, a tool used to build Fedora packages some time ago. [ ]
- Drop an unused function. [ ]
- Various documentation improvements. [ ][ ]
- Improve the node health check to detect zombie jobs. [ ]
-
Jessica Clarke (FreeBSD-related changes):
-
Mattia Rizzolo:
- Block F-Droid jobs from running whilst the setup is running. [ ]
- Enable debugging for the
rsync job related to Debian Live images. [ ]
- Pass
BUILD_TAG and BUILD_URL environment for the Debian Live jobs. [ ]
- Refactor the
master_wrapper script to use a Bash array for the parameters. [ ]
- Prefer YAML s
safe_load() function over the unsafe variant. [ ]
- Use the correct variable in the Apache config to match possible existing files on disk. [ ]
- Stop issuing HTTP 301 redirects for things that not actually permanent. [ ]
-
Roland Clobus (Debian live image generation):
- Increase the diffoscope timeout from 120 to 240 minutes; the Cinnamon image should now be able to finish. [ ]
- Use the new snapshot service. [ ]
- Make a number of improvements to artifact handling, such as moving the artifacts to the Jenkins host [ ] and correctly cleaning them up at the right time. [ ][ ][ ]
- Where possible, link to the Jenkins build URL that created the artifacts. [ ][ ]
- Only allow only one job to run at the same time. [ ]
-
Vagrant Cascadian:
- Temporarily disable
armhf nodes for DebConf21. [ ][ ]
Lastly, if you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. You can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter (@ReproBuilds) and Mastodon (@reproducible_builds@fosstodon.org).
-
Reddit: /r/ReproducibleBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
-
Bernhard M. Wiedemann:
awkward(timestamp issue)ck(build fails in single-CPU mode)cri-o(build ID issue related to Go parallelism)kernel-obs-build(cpiometadata issue)python-PyQt6(.pyc-related issue)python-dulwich(fails to build in 2023)python-xkbgroup(.pyc-related issue)rnp(fails to build in 2024)
-
Bj rn Forsman:
dosfstools(from December 2018) was eventually merged.
-
Chris Lamb:
- #992039 filed against
mapcache. - #992059 filed against
spatialindex. - #992060 filed against
pytsk. - #992061 filed against
surgescript. - #992126 filed against
rust-coreutils. - #992772 filed against
translate. - #992773 filed against
spirv-cross. - #992804 filed against
numcodecs. - #993279 filed against
tty-solitaire. - #993304 filed against
samtools.
- #992039 filed against
-
Simon McVittie:
- #992620 filed against
pkg-config. - #992622 filed against
pkgconf. - #992645 filed against
ncftp. - #992647 filed against
backuppc. - #992651 filed against
sharutils. - #992662 filed against
cfengine3. - #992702 filed against
nbdkit. - #992722 filed against
nbdkit. - #992775 filed against
python3.9. - #992781 filed against
supermin. - #992782 filed against
virt-p2v. - #993249 filed against
gnunet. - #993250 filed against
mpb. - #993275 filed against
ng.
- #992620 filed against
- Vagrant Cascadian:
Elsewhere, it was discovered that when supporting various new language features and APIs for Android apps, the resulting APK files that are generated now vary wildly from build to build (example diffoscope output). Happily, it appears that a patch has been committed to the relevant source tree. This was also discussed on our mailing list this month in a thread titled Android desugaring and reproducible builds started by Marcus Hoffmann.
Website and documentation
There were quite a few changes to the Reproducible Builds website and documentation this month, including:
-
Felix C. Stegerman:
-
Holger Levsen:
- Add a new page documenting various package rebuilder solutions. [ ]
- Add some historical talks and slides from DebConf20. [ ][ ]
- Various improvements to the history page. [ ][ ][ ]
- Rename the Comparison protocol documentation category to Verification . [ ]
- Update links to F-Droid documentation. [ ]
-
Ian Muchina:
-
Mattia Rizzolo:
- Drop a
position:fixed CSS statement that is negatively affecting with some width settings. [ ]
- Fix the sizing of the elements inside the side navigation bar. [ ]
- Show gold level sponsors and above in the sidebar. [ ]
- Updated the documentation within
reprotest to mention how ldconfig conflicts with the kernel variation. [ ]
-
Roland Clobus:
- Added a ticket number for the issue with the live Cinnamon image and diffoscope. [ ]
Testing framework
The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
-
Holger Levsen:
-
Debian-related changes:
- Make a large number of changes to support the new Debian bookworm release, including adding it to the dashboard [ ], start scheduling tests [ ], adding suitable Apache redirects [ ] etc. [ ][ ][ ][ ][ ]
- Make the first build use
LANG=C.UTF-8 to match the official Debian build servers. [ ]
- Only test Debian Live images once a week. [ ]
- Upgrade all nodes to use Debian Bullseye [ ] [ ]
- Update README documentation for the Debian Bullseye release. [ ]
-
Other changes:
- Only include
rsync output if the $DEBUG variable is enabled. [ ]
- Don t try to install
mock, a tool used to build Fedora packages some time ago. [ ]
- Drop an unused function. [ ]
- Various documentation improvements. [ ][ ]
- Improve the node health check to detect zombie jobs. [ ]
-
Jessica Clarke (FreeBSD-related changes):
-
Mattia Rizzolo:
- Block F-Droid jobs from running whilst the setup is running. [ ]
- Enable debugging for the
rsync job related to Debian Live images. [ ]
- Pass
BUILD_TAG and BUILD_URL environment for the Debian Live jobs. [ ]
- Refactor the
master_wrapper script to use a Bash array for the parameters. [ ]
- Prefer YAML s
safe_load() function over the unsafe variant. [ ]
- Use the correct variable in the Apache config to match possible existing files on disk. [ ]
- Stop issuing HTTP 301 redirects for things that not actually permanent. [ ]
-
Roland Clobus (Debian live image generation):
- Increase the diffoscope timeout from 120 to 240 minutes; the Cinnamon image should now be able to finish. [ ]
- Use the new snapshot service. [ ]
- Make a number of improvements to artifact handling, such as moving the artifacts to the Jenkins host [ ] and correctly cleaning them up at the right time. [ ][ ][ ]
- Where possible, link to the Jenkins build URL that created the artifacts. [ ][ ]
- Only allow only one job to run at the same time. [ ]
-
Vagrant Cascadian:
- Temporarily disable
armhf nodes for DebConf21. [ ][ ]
Lastly, if you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. You can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter (@ReproBuilds) and Mastodon (@reproducible_builds@fosstodon.org).
-
Reddit: /r/ReproducibleBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
- Add a new page documenting various package rebuilder solutions. [ ]
- Add some historical talks and slides from DebConf20. [ ][ ]
- Various improvements to the history page. [ ][ ][ ]
- Rename the Comparison protocol documentation category to Verification . [ ]
- Update links to F-Droid documentation. [ ]
- Drop a
position:fixedCSS statement that is negatively affecting with some width settings. [ ] - Fix the sizing of the elements inside the side navigation bar. [ ]
- Show gold level sponsors and above in the sidebar. [ ]
- Updated the documentation within
reprotestto mention howldconfigconflicts with the kernel variation. [ ]
- Added a ticket number for the issue with the live Cinnamon image and diffoscope. [ ]
The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
-
Holger Levsen:
-
Debian-related changes:
- Make a large number of changes to support the new Debian bookworm release, including adding it to the dashboard [ ], start scheduling tests [ ], adding suitable Apache redirects [ ] etc. [ ][ ][ ][ ][ ]
- Make the first build use
LANG=C.UTF-8to match the official Debian build servers. [ ] - Only test Debian Live images once a week. [ ]
- Upgrade all nodes to use Debian Bullseye [ ] [ ]
- Update README documentation for the Debian Bullseye release. [ ]
-
Other changes:
- Only include
rsyncoutput if the$DEBUGvariable is enabled. [ ] - Don t try to install
mock, a tool used to build Fedora packages some time ago. [ ] - Drop an unused function. [ ]
- Various documentation improvements. [ ][ ]
- Improve the node health check to detect zombie jobs. [ ]
- Only include
-
Debian-related changes:
- Jessica Clarke (FreeBSD-related changes):
-
Mattia Rizzolo:
- Block F-Droid jobs from running whilst the setup is running. [ ]
- Enable debugging for the
rsyncjob related to Debian Live images. [ ] - Pass
BUILD_TAGandBUILD_URLenvironment for the Debian Live jobs. [ ] - Refactor the
master_wrapperscript to use a Bash array for the parameters. [ ] - Prefer YAML s
safe_load()function over the unsafe variant. [ ] - Use the correct variable in the Apache config to match possible existing files on disk. [ ]
- Stop issuing HTTP 301 redirects for things that not actually permanent. [ ]
-
Roland Clobus (Debian live image generation):
- Increase the diffoscope timeout from 120 to 240 minutes; the Cinnamon image should now be able to finish. [ ]
- Use the new snapshot service. [ ]
- Make a number of improvements to artifact handling, such as moving the artifacts to the Jenkins host [ ] and correctly cleaning them up at the right time. [ ][ ][ ]
- Where possible, link to the Jenkins build URL that created the artifacts. [ ][ ]
- Only allow only one job to run at the same time. [ ]
-
Vagrant Cascadian:
- Temporarily disable
armhfnodes for DebConf21. [ ][ ]
- Temporarily disable
Lastly, if you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. You can get in touch with us via:
-
IRC:
#reproducible-buildsonirc.oftc.net. - Twitter (@ReproBuilds) and Mastodon (@reproducible_builds@fosstodon.org).
- Reddit: /r/ReproducibleBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
 After a seven-year break (!!), the
After a seven-year break (!!), the  After a
After a  (Yes, this got in the way of working out what was going on with
(Yes, this got in the way of working out what was going on with  This isn t completely satisfying as we never quite got to the bottom of the
leak itself, and it s entirely possible that we ve only papered over it
using
This isn t completely satisfying as we never quite got to the bottom of the
leak itself, and it s entirely possible that we ve only papered over it
using  Here is my monthly update covering what I have been doing in the free software world during July 2021 (
Here is my monthly update covering what I have been doing in the free software world during July 2021 (

 The pandemic was a bit of a mess for most FLOSS conferences. The two
conferences that I help organize --
The pandemic was a bit of a mess for most FLOSS conferences. The two
conferences that I help organize -- 
 .
On the global stage, about a decade ago, Stephen J. Dubner and Steven Levitt argued in their book
.
On the global stage, about a decade ago, Stephen J. Dubner and Steven Levitt argued in their book 


 Pappu Yadav, President Jan Adhikar Party, Bihar May 11, 2021
Pappu Yadav, President Jan Adhikar Party, Bihar May 11, 2021





 I ve mostly had the preference of controlling my data rather than depend on someone else. That s one reason why I still believe email to be my most reliable medium for data storage, one that is not plagued/locked by a single entity. If I had the resources, I d prefer all digital data to be broken down to its simplest form for storage, like email format, and empower the user with it i.e. their data.
Yes, there are free services that are indirectly forced upon common users, and many of us get attracted to it. Many of us do not think that the information, which is shared for the free service in return, is of much importance. Which may be fair, depending on the individual, given that they get certain services without paying any direct dime.
I ve mostly had the preference of controlling my data rather than depend on someone else. That s one reason why I still believe email to be my most reliable medium for data storage, one that is not plagued/locked by a single entity. If I had the resources, I d prefer all digital data to be broken down to its simplest form for storage, like email format, and empower the user with it i.e. their data.
Yes, there are free services that are indirectly forced upon common users, and many of us get attracted to it. Many of us do not think that the information, which is shared for the free service in return, is of much importance. Which may be fair, depending on the individual, given that they get certain services without paying any direct dime.

 Google Pixel phones support what they call Motion Photo which is essentially a photo with a short video clip attached to it. They are quite nice since they bring the moment alive, especially as the capturing of the video starts a small moment before the shutter button is pressed. For most viewing programs they simply show as static JPEG photos, but there is more to the files.
Google Pixel phones support what they call Motion Photo which is essentially a photo with a short video clip attached to it. They are quite nice since they bring the moment alive, especially as the capturing of the video starts a small moment before the shutter button is pressed. For most viewing programs they simply show as static JPEG photos, but there is more to the files. 
 Creating Beautiful Github Streaks
Github streaks are a pretty fun and harmless way of visualizing your
contributions on github or gitlab. Some people use them to brag a little, some
companies use them to check out potential candidates. It s all good as long as
everyone is aware how easily you can manipulate them.
In order to fake a commit date in the past, you have to set the
Creating Beautiful Github Streaks
Github streaks are a pretty fun and harmless way of visualizing your
contributions on github or gitlab. Some people use them to brag a little, some
companies use them to check out potential candidates. It s all good as long as
everyone is aware how easily you can manipulate them.
In order to fake a commit date in the past, you have to set the
 I know, I m for sure not the first one to discover this kind of thing, but it
was a fun afternoon project anyways!
I know, I m for sure not the first one to discover this kind of thing, but it
was a fun afternoon project anyways!